 |
CORIS/CODIS
Design and implementation of a CORpus di Italiano
Scritto
|
1.
To describe the realisation of CORIS briefly, the
principle phases may be indicated as follows:
- Corpus design
- Corpus typology
- Corpus size
- Representativeness
- Design of source text framework
- Text typology
- Text unit size
- Definition of selection criteria
- Corpus structure
- Subcorpora definition
- Subcorpora-to-subcorpora ratio
- Definition of sampling criteria
- Source data collection and corpus building
- Part-of-speech tagging and lemmatisation
2.
In order to design and construct CORIS, some preliminary choices were
necessary to lay the foundations for successive stages. First of all
the aim of the project was defined, and the type of corpus it was
intended to create. From the very beginning, the purpose of the project
was identified as being a general corpus, as
defined by the Brown Corpus, one of the first electronic corpora.
Just as the Brown Corpus was referred to as "a standard sample of
present-day English for use with digital computers", so too the aim of
CORIS, at the design stage, could be identified with the creation of a
collection of texts in electronic format which represent, in the widest
sense, present-day Italian. The identification of this aim provided a
solution to one of the first problems which arose in the planning of
the corpus, the choice between synchronic and diachronic dimensions. It
was decided to select texts synchronically in order to permit a
generalised description of commonly used Italian.
The choice between written or spoken language gave
rise to greater problems. Having taken into account various
possibilities, bearing in mind the obvious advantages of having a
corpus with both written and spoken texts, it was decided to give
priority to written texts at this stage of research. The decision was
based both on external and internal criteria. First of all, it was
influenced by the general panorama of Italian linguistics and the
position that the corpus would occupy alongside
works such as Lessico di frequenza dell'italiano parlato (LIP,
1993), Lessico di frequenza della
lingua italiana contemporanea (LIF,1972),
Vocabolario elettronico elettronico della lingua
italiana. Il vocabolario del 2000 (VELI, 1989), Corpus
di italiano parlato (Cresti 2000) and LIZ ( Letteratura
Italiana Zanichelli in cd-rom (1993,1995, 1997) to name just
the most important. We should also mention the Italian
Reference Corpus (1991) and the Italian Corpus
Documentation PAROLE (1998) both developed at the ILC by the
the Pisa CNR. Secondly, in the light of transformations in
communication by new technologies, it was preferred not to pose the
problem of the relationship between the language traditionally
considered as standard spoken Italian and its technological
ramifications via telephone, radio, television and/or computer
technology.
For these reasons, the choice fell upon a synchronic
corpus of written language, whose component texts belong,
roughly speaking, to the 1980s and 1990s, with a somewhat wider
temporal collocation as far as narrative is concerned. They belong to
an Italian language which, using the criteria determined by Nencioni
(1983), can be described as written-written.
The definition of the size of CORIS required
greater thought. A study of presently available corpora clearly
revealed that it was not possible to make reference to any standard
size. The rapid and widespread development which has characterised,
especially in recent years, both the low-cost availability of hardware
as well as the production of ever more efficient
and user-friendly software, has radically transformed the criteria for
the creation of the most recent corpora compared
with those of the first or second generation.
While the criteria on which first generation
corpora, such as the Brown Corpus, were based may have been mainly
influenced by the potentiality of information technology, present-day
technology no longer sets any limits to the choices of the researcher,
who can extend a corpus to include the varieties
held to be relevant to his/her analysis and, within these, make a
suitable selection of the varieties of representative texts.
Developments in information technology over the past years, the present
speed of the processing of material and the low cost of mass storage
units mean that it is possible to create corpora consisting of hundreds
of millions of words, such as the British National Corpus and the Bank
of English. It would seem that, especially as far as written language
is concerned, the standard of one million words has given way to a
standard of one hundred million. However, any generalisation appears to
be debatable, as is any definition of an obligatory limit. The Brown
Corpus (1967), with one million words, 500 written text samples of 2000
words each, representing in equal measure the main text types, is still
considered by many scholars to be a valid model. One of the most recent
English language corpora, the Longman Spoken and Written English Corpus
- LSWE Corpus - created by scholars like Biber, Johnson, Leech, Conrad
and Finegan, consists of about 40,000,000 words and contains 37,244
texts. It is claimed, that these texts vary in length according to
register.
A further aspect to be considered in the
definition of a corpus relates to the introduction of monitor corpora.
These provide for constant updating by means of the periodic
introduction of data realised by a collection of filters, on the basis
of a selection carried out both on fresh data and on those already
introduced. The configuration of the monitor corpus
means that the aspects of determinacy
and permanence which were defining characteristics of the size of a corpus
over the past decades are no longer valid. The corpus takes on a
dynamic configuration, which seems more relevant and advantageous if we
consider that today, with the new possibilities provided by the
development of new technology and memory, it is no longer necessary to
go to the trouble of selecting texts. It seems to be possible to manage
a corpus whose principal components are delimited and, at the same
time, a monitor corpus which is open and able to record innovations and
modifications in current usage. This combination makes it possible to
access a corpus which is available in a finite form - either on-line or
on CD-Rom - and which can be updated by means of the monitor as well as
by the introduction of supplementary subcorpora representing further
varieties.
It was therefore decided to proceed with the
planning of a corpus whose size, though configured as "large", was not
predetermined but relative to the choice of linguistic varieties
thought to be representative and, as such, set as an intermediate
research goal following the compilation of a pilot corpus.
The definition of representativeness is a crucial
point in the creation of a corpus, but it is one of the most
controversial aspects among specialists, especially as regards the
ambiguity inherent in its use due to the intermingling of quantitative
and qualitative connotations. While for some scholars the extension of
corpora to include hundreds of millions of words might make up for a
slight differentiation in the varieties represented, for others a wide
differentiation in varieties is set as an essential condition for any
act of generalisation.
As far as we were concerned, even in the first
phase of research the problem of representativeness did not, in our
opinion, disappear with the possibility of enlarging the corpus;
indeed, it was underlined even more. In spite of the size increase to
hundreds of millions of words, each corpus represents a limited sample
of language in use. An operation of sampling, however extensive it may
be, inevitably turns out to be simplified in the light of the
complexity of the phenomenon under examination. Even building random
selections into the corpus construction, it seemed to us that in the
transition from the sample to the generalisation, certain degrees of
approximation should be provided for, thus allowing maximum flexibility
and dynamics in the proposed model.
In the light of problems of what I would call an
epistemological nature encountered in the planning of a corpus which
could unarguably be defined as being representative of a language or of
the state of a language, it was decided to proceed recognising the
limits inherent in the project itself and identifying parameters which
might eventually counterbalance those limits. Some criteria of
identification for the parameters of reference were thus defined which
permitted the creation of a collection of sub-corpora which included
the chief varieties of written Italian, represented and appropriately
balanced. It appeared possible, at the same time, to obtain the
elaboration of a model of dynamic and adaptive creation which would
satisfy the needs and working hypotheses of different scholars while
still respecting the criteria of corpus construction.
3.
In the context of corpus linguistics, one of the
basic criteria accepted by all projects and studies is the fact that
selected texts must be authentic and commonly used in social
interaction. There is however no consensus as to whether to insert
texts in their entirety or in fragments which may be defined as being
representative. This is indeed a crucial point and was the object of
considerable reflection during the planning phase. As we have seen, in
the first corpora, such as Brown, standardised
sampling was applied. Uniformity of text size is one of the basic
construction principles. If there was disagreement, this focused upon
the size of the samples. In the designing of the construction model it
was held that, considering the present conditions created by software
programs, the problem is not so much that of defining sample
size but rather of the choice to be made between texts and
texts fragments.
The first inevitably leads to a lack of
standardisation of text samples. It is rarely the case that several
texts, whether they be journalistic, narrative or scientific, contain
the same number of words. The second, on the other hand, may lead to a
stronger influence of the researcher's subjective judgment and implies
that the selected sequence is taken out of context. This could mean
that the larger size invalidates the very representativeness of the
corpus. It was therefore decided that, where possible, the entire text
would be entered, rather than standardising sample size.
A later step was the definition of linguistic
varieties used to create the corpus.
These are considered as a collection of documents identifiable on the
basis of both external and internal features, in which the peculiarity
of the single variety fades away in comparison to the mass of data.
This constituted one of the most important points. Although the corpus
included specialist areas, such as legal, scientific and
bureaucratic-administrative language, an attempt was made to bring
together not so much a collection of specialist texts as a variety of
types which, according to our investigations, can be placed within a
continuum, overlapping and integrating one and another.
When defining the selection and creation
criteria reference was made to both external and internal
criteria in order to reduce the researcher's interference to a minimum.
Furthermore, considering the scientific context
of CORIS as well as the wide availability of existing and planned
corpora, a further criterion was introduced, that of "comparability",
in order to offer scholars the possibility of interlinguistic
comparison of corpora.
4.
In order to define a first level of articulation
of a corpus, what I would describe as criteria of external textuality
and comparability were of prime importance. These led to the
configuration of a first level of articulation -
provided by the sub-corpora - in which it was
possible to refer to some macro-varieties
identified on the basis of external appearance or the material elements
of the text, extremely clear in their characterisation and easily
comparable. The subjective choices of the researcher would thus be
reduced to a minimum.
As distinction between "published" and
"unpublished" texts was considered to be too simple, various forms of
publications from the "press", "narrative" from various types of
volumes and essays identified as miscellaneous were then selected, and
various hand-written, printed and above all electronic texts were
grouped together in a section under the heading of "ephemera" due to
their transitory nature.
Having defined these macro-varieties, it was
thought necessary to apply a second level of articulation -
based on the sections which could be divided into subsections
- which, again using external parameters as a basis, still allowed
collected data to be contextualised. For example, it was clear that a
sampling of the "press" population could not be undertaken except on
the basis of a second articulation connected to the socio-cultural
reality of the nation. This was considered to be a fundamental point in
order to arrive at a definition of a population's components, albeit
with some degree of approximation.
The reference to the above-mentioned parameters
led to the configuration of the following structure:
| Subcorpus |
PRESS |
| Sections |
newspapers, periodic, supplement |
| Subsections |
national, local
specialist, non specialist
connotated, non connotated |
| Subcorpus |
FICTION |
| Sections |
novels, short stories |
| Subsections |
Italian,
foreign
for adults, for children
crime, adventure, science-fiction, women literature |
| Subcorpus |
ACADEMIC PROSE |
| Sections |
human sciences, natural
sciences, physics, experimental sciences |
| Subsections |
books,
reviews
scientific, popularhistory, philosophy, arts, literary criticism,
law,
economy, biology, etc. |
| Subcorpus |
LEGAL AND ADMINISTRATIVE
PROSE |
| Sections |
legal, bureaucratic,
administrative |
| Subsections |
books,
reviews |
| Subcorpus |
MISCELLANEA |
| Sections |
books on religion,
travel, cookery, hobbies, etc. |
| Subsections |
books,
reviews |
| Subcorpus |
EPHEMERA |
| Sections |
letters, leaflets,
instructions |
| Subsections |
private,
public
printed form, electronic form |
Subsections
Having defined the selection criteria, the next
step was the planning of the sub-corpora, first
taking into consideration an examination of the size they
should have and the ratio between the size of the
various subcorpora and sections.
An initial idea was to consider the possibility of
working on the basis of a randomised selection and to correlate the
dimensions of each subgroup of texts to the number, albeit approximate,
of the recipients of a given text. The application of quantitative
parameters - such as circulation and distribution - proved to be too
limiting - in comparison with qualitative parameters such as time and
type of text use or level of cognitive attention. So despite the
difficulties involved in the introduction of qualitative (hence
non-measurable) parameters, it was our opinion that merely quantitative
data were not sufficiently significant and that they should be
integrated, as far as the percentage ratios between sub-corpora and
sections was concerned, with qualitative variables, lest any one
variety should be overestimated. This choice of procedure was
corroborated by an in-depth analysis for 1997:
| PRESS
(data derived from FIEG, La stampa
in Italia 1995-1998, Milano, 1999)
|
BOOKS
(data derived from AIE, La
produzione libraria italiana del 1997, Milano, 1999)
|
| Newspapers
2 955 501 360
Weekly magazines
730 364 544
Monthly magazines
194 607 972
|
Fiction
119 100 000
Non-fiction 179 400 000
|
| TOTAL
3 880 473 876 |
TOTAL
298 500 000 |
The ratio of 1:12 established, more or less,
between texts from the mass media and texts from the book market could
not be accepted as being reproducible in the samples. On the other
hand, it appeared to be too relevant to ignore, even bearing in mind
the comparability of the corpus under construction. Within the ratio
allowed by the sales volumes, which, on the basis of the data, is
represented as an interval, it was decided to set the ratio between the
different areas of circulation as the smallest allowed value in order
not to penalise certain textual varieties, such as letters.
Having selected a wide range of linguistic
varieties, documents for the entry of the single sub-corpora were
prepared and, in order to comply with the criterion of
representativeness, the documents were randomized within each
sub-corpus. Having defined this objective corpus framework, the
following macro-varieties were defined:
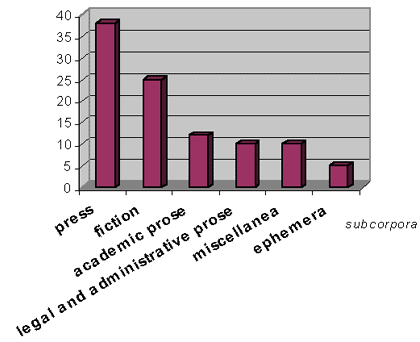
PRESS - 38 million words
FICTION - 25 million words
ACADEMIC PROSE - 12 million words
LEGAL AND ADMINISTRATIVE PROSE - 10 million words
MISCELLANEA -10 million words
EPHEMERA - 5 million words
5.
A corpus of written Italian - a defined
model and a dynamic model.
Therefore, the corpus of written Italian - CORIS -
appears to be defined along general lines as:
a collection of texts which are
authentic, commonly occurring, in electronic format, chosen as
representative of present-day Italian
and in terms of size as:
a general corpus consisting of 100
million words updated every two years by means of a monitor corpus
CORIS was designed and built as a general
reference corpus for the analysis of written Italian and will be placed
on-line by June 2001.
At the same time, considering the vital role which
will be played by the comparability of a reference corpus, it seemed
important to provide for the possibility of creating an alternative
corpus structure which would make it adaptable to the needs of
different researchers. Besides CORIS, a further corpus - CODIS - has
been designed. Aimed at specialist needs which might arise in the
context of interlinguistic analysis, CODIS presents a dynamic and
adaptive structure that allows the selection of the subcorpora which
are pertinent to a specific research project and also the size of every
single sub-corpus. CODIS is designed to be dynamically adapted to
different comparative needs.
|
Subcorpus
|
User-selectable
sizes (Mw)
|
| PRESS |
20
|
10
|
5
|
3
|
| FICTION |
13
|
7
|
3
|
2
|
| ACADEMIC PROSE |
5
|
4
|
2
|
1
|
| LEGAL & ADMIN. PROSE |
4
|
3
|
2
|
1
|
| Miscellanea |
4
|
3
|
2
|
1
|
| Ephemera |
2
|
1
|
1
|
1
|
|
